Introduction
Recent years have witnessed a rapid spread of fake news on social platforms, where images and text are tightly coupled. In multimodal settings, out-of-context image–text pairs and old images reused for new stories make fake news detection particularly challenging, because visually persuasive content can easily mask subtle semantic inconsistencies.
Existing multimodal fake news detection methods mainly focus on representation learning, cross-modal fusion, and external evidence retrieval, and most LVLM-based approaches optimize task loss without directly intervening in the hallucination mechanisms of large vision–language models. As a result, models remain vulnerable to completion-style hallucinations driven by language priors, especially in high-risk cases with image–text inconsistency and temporal drift.
To address this gap, we propose VisGOR, a training-free, plug-and-play framework for cross-modal attention calibration. VisGOR combines Focus-Zone Distortion (FZD), which derives visual evidence priors from model-internal signals, with Evidence-Gated Attention Recalibration (EGAR), which performs uncertainty-aware reallocation of query→image attention and yields evidence-grounded captions in a “suppress-then-compare” pipeline. Extensive experiments on POPE, MS-COCO (CHAIR), Fakeddit, and Yang demonstrate that VisGOR reduces hallucinations, improves multimodal fake news detection, and offers interpretable visual evidence for human auditing.
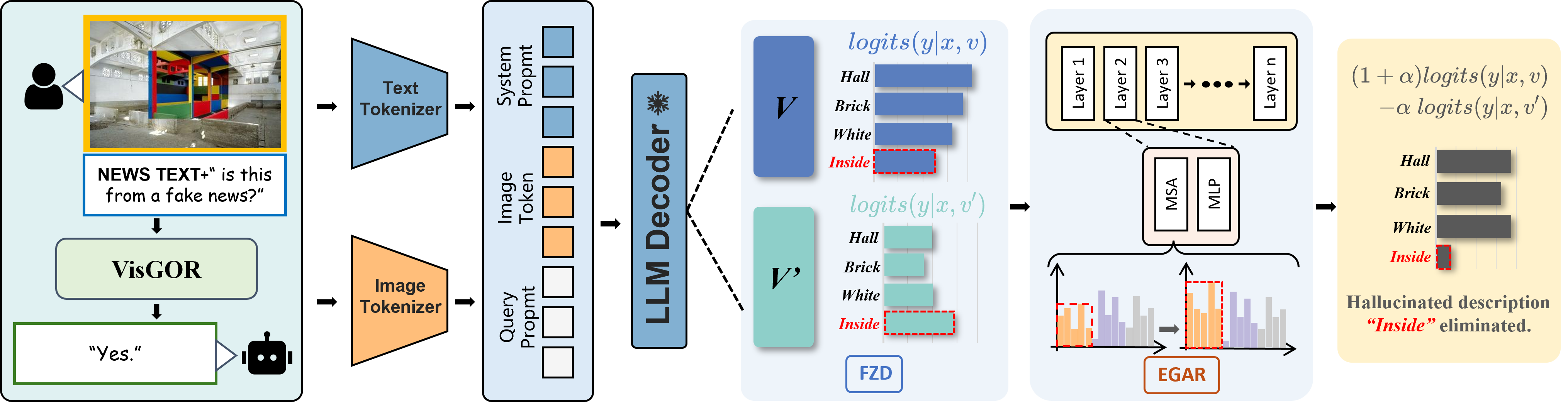
Figure 1: Overall architecture of VisGOR. FZD (Fake-news evidence Detection) locates image regions that are semantically aligned with the input news text, and EGAR (Evidence-Gated Attention Recalibration) modulates cross-modal attention during decoding so that the LVLM focuses on evidence-centric regions while suppressing spurious ones.
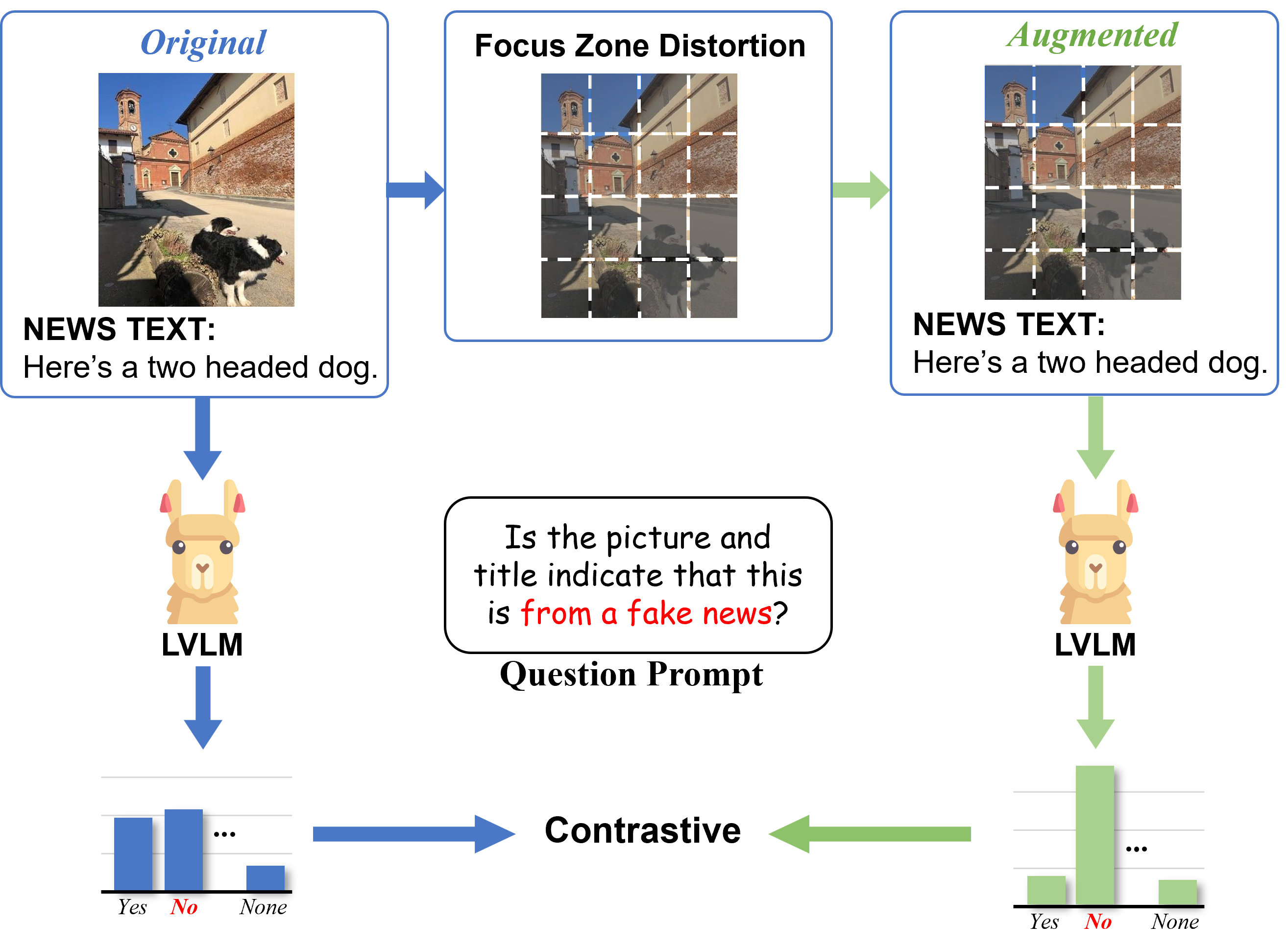
Figure 2: Illustration of Focus-Zone Distortion (FZD). Given a news item, FZD constructs original and distorted views, restricts contrast to prompt-aligned regions, and outputs a visual-evidence prior that later guides EGAR.
Results
We evaluate VisGOR on four benchmarks: Fakeddit and Yang for multimodal fake news detection, POPE for object-level hallucination under the VQA paradigm, and CHAIR on MS-COCO for open-ended caption hallucination. Below we report the main quantitative results corresponding to the paper.
Fake News Detection on Fakeddit and Yang
On the large-scale Fakeddit benchmark, we perform binary real-versus-fake classification using Qwen2.5-VL as the backbone and compare VisGOR with strong multimodal fake news detection baselines including EANN, MVAE, MTTV, BMR, and GAMED. VisGOR improves overall Accuracy from 91.56% to 92.03% and F1 from 91.94% to 92.07% over the strongest baseline GAMED, without any additional LVLM training. The gains are particularly pronounced for samples with image–text inconsistency or old-image–new-story patterns, where FZD and EGAR jointly reduce hallucinated visual evidence and yield more reliable fake-news decisions across diverse subcommunities.
On the Yang news dataset, which contains 20,015 image–text articles from over 240 websites and major outlets, we again use Qwen2.5-VL as the backbone and compare VisGOR with EANN, MVAE, SAFE, BMR, and GAMED. VisGOR achieves the best overall performance, improving Accuracy from 96.00% to 96.12% and F1 from 96.03% to 96.36% over GAMED. The method is particularly effective on fake-news instances where misleading content hinges on subtle temporal or contextual cues, as stronger visual grounding during caption generation reduces hallucinated supporting details and makes the text–description inconsistency signal more dependable.
| Dataset |
Method |
Accuracy (%) |
Precision (%) |
Recall (%) |
F1-Score (%) |
| Fakeddit |
EANN |
86.19 |
88.71 |
86.17 |
88.01 |
| MVAE |
87.62 |
89.03 |
89.29 |
89.74 |
| MTTV |
89.86 |
92.78 |
91.73 |
91.29 |
| BMR |
90.64 |
93.74 |
91.49 |
91.85 |
| GAMED |
91.56 |
91.40 |
92.58 |
91.94 |
| Ours |
92.03 |
93.06 |
92.64 |
92.07 |
| Yang |
EANN |
84.09 |
84.57 |
83.14 |
83.33 |
| MVAE |
90.13 |
90.48 |
88.67 |
89.89 |
| SAFE |
90.98 |
92.06 |
91.57 |
92.54 |
| BMR |
92.17 |
93.61 |
92.59 |
92.36 |
| GAMED |
96.00 |
95.98 |
96.57 |
96.03 |
| Ours |
96.12 |
96.07 |
95.59 |
96.36 |
POPE: Discrimination Hallucination Benchmark
On the POPE benchmark, we evaluate VisGOR on LLaVA-1.5 and Qwen2.5-VL under the Random, Popular, and Adversarial settings, comparing against vanilla decoding and inference-time baselines such as VCD and IMCCD with Accuracy, Precision, Recall, and F1. VisGOR consistently reduces object hallucinations, improving Accuracy by about 0.39%–1.96% and F1 by 0.93%–2.66% over VCD, with simultaneous gains in Precision and Recall. These results show that evidence-gated attention calibration substantially strengthens LVLM robustness on challenging yes/no hallucination probes without any additional training.
| Model |
Setting |
Decoding |
Accuracy ↑ |
Precision |
Recall |
F1 Score ↑ |
| LLaVA-1.5 |
Random |
Vanilla |
83.49 |
88.84 |
76.76 |
82.28 |
| VCD |
86.84 |
87.15 |
86.68 |
86.83 |
| AGLA |
88.54 |
94.41 |
82.08 |
87.71 |
| IMCCD |
88.78 |
91.61 |
85.56 |
88.28 |
| Ours |
88.80 |
89.82 |
87.87 |
88.66 |
| Popular |
Vanilla |
79.98 |
82.47 |
76.76 |
79.34 |
| VCD |
82.65 |
80.59 |
86.68 |
83.37 |
| AGLA |
85.14 |
87.88 |
82.08 |
84.68 |
| IMCCD |
85.53 |
85.61 |
85.73 |
85.57 |
| Ours |
83.04 |
84.04 |
87.87 |
85.91 |
| Adversarial |
Vanilla |
76.03 |
76.11 |
76.80 |
76.26 |
| VCD |
77.31 |
73.43 |
86.47 |
79.28 |
| AGLA |
81.13 |
81.20 |
82.10 |
81.36 |
| IMCCD |
80.31 |
77.73 |
85.55 |
81.33 |
| Ours |
78.23 |
76.67 |
87.89 |
81.80 |
| Qwen2.5-VL |
Random |
Vanilla |
90.18 |
96.49 |
83.49 |
89.44 |
| VCD |
89.45 |
96.14 |
82.31 |
88.61 |
| AGLA |
88.44 |
96.84 |
79.49 |
87.38 |
| IMCCD |
90.86 |
95.50 |
85.75 |
90.37 |
| Ours |
90.89 |
96.54 |
86.55 |
91.27 |
| Popular |
Vanilla |
87.56 |
91.21 |
83.49 |
88.41 |
| VCD |
86.80 |
90.41 |
82.71 |
86.21 |
| AGLA |
85.64 |
94.32 |
79.71 |
85.63 |
| IMCCD |
87.55 |
88.98 |
85.75 |
87.32 |
| Ours |
87.57 |
91.30 |
84.55 |
87.80 |
| Adversarial |
Vanilla |
82.02 |
82.36 |
81.56 |
81.82 |
| VCD |
83.81 |
85.29 |
82.58 |
83.65 |
| AGLA |
83.89 |
87.33 |
80.20 |
82.91 |
| IMCCD |
83.86 |
82.57 |
85.84 |
84.17 |
| Ours |
84.70 |
86.09 |
83.60 |
84.58 |
CHAIR on MS-COCO Caption Generation
For open-ended captioning on MS-COCO, we follow the CHAIR protocol and compare VisGOR with vanilla decoding and contrastive baselines on LLaVA-1.5 and Qwen2.5-VL, reporting CHAIR-s, CHAIR-i, and Recall. VisGOR reduces both CHAIR-s and CHAIR-i by roughly 1%–3% while achieving a clear gain in Recall, indicating that captions contain fewer hallucinated objects yet cover more true objects rather than merely “saying less.” Overall, CHAIR results confirm that VisGOR effectively suppresses completion-style hallucinations in long-form captions while preserving rich and faithful visual descriptions.
| Model |
Method |
CS ↓ |
CI ↓ |
Precision ↑ |
| LLaVA-1.5 |
Vanilla |
55.6 |
17.8 |
82.2 |
| VCD |
54.2 |
16.4 |
83.6 |
| AGLA |
43.0 |
14.1 |
85.9 |
| IMCCD |
49.8 |
13.8 |
86.3 |
| Ours |
48.3 |
13.6 |
86.4 |
| Qwen2.5-VL |
Vanilla |
41.2 |
11.5 |
88.5 |
| VCD |
44.4 |
12.3 |
87.7 |
| AGLA |
29.2 |
8.7 |
91.3 |
| IMCCD |
34.0 |
8.5 |
91.5 |
| Ours |
33.8 |
8.3 |
91.7 |
Conclusion
In this work, we revisited multimodal fake news detection from the perspective of hallucination mitigation in large vision–language models. We proposed VisGOR, a training-free and plug-and-play decoding framework that explicitly anchors LVLM generation to evidence-bearing image regions through two modules: FZD, which derives a visual-evidence prior, and EGAR, which selectively reallocates query-to-image attention during decoding in a two-stage “suppress-then-compare” pipeline. Extensive experiments on POPE and CHAIR show that VisGOR effectively suppresses object hallucinations while preserving descriptive power. On the Fakeddit and Yang benchmarks, VisGOR consistently improves overall accuracy and F1 over strong multimodal FND baselines, demonstrating that hallucination-aware decoding can directly enhance the reliability of multimodal fake news detection.
